Model Deployment
Batch prediction VS Online prediction
ML Deployment Myths
- you only deploy one or two models at a time
- if we don’t do anything, model performance remain the same
- you won’t need to update your model as much
- most ML Engineers don’t need to worry about scale
Batch prediction

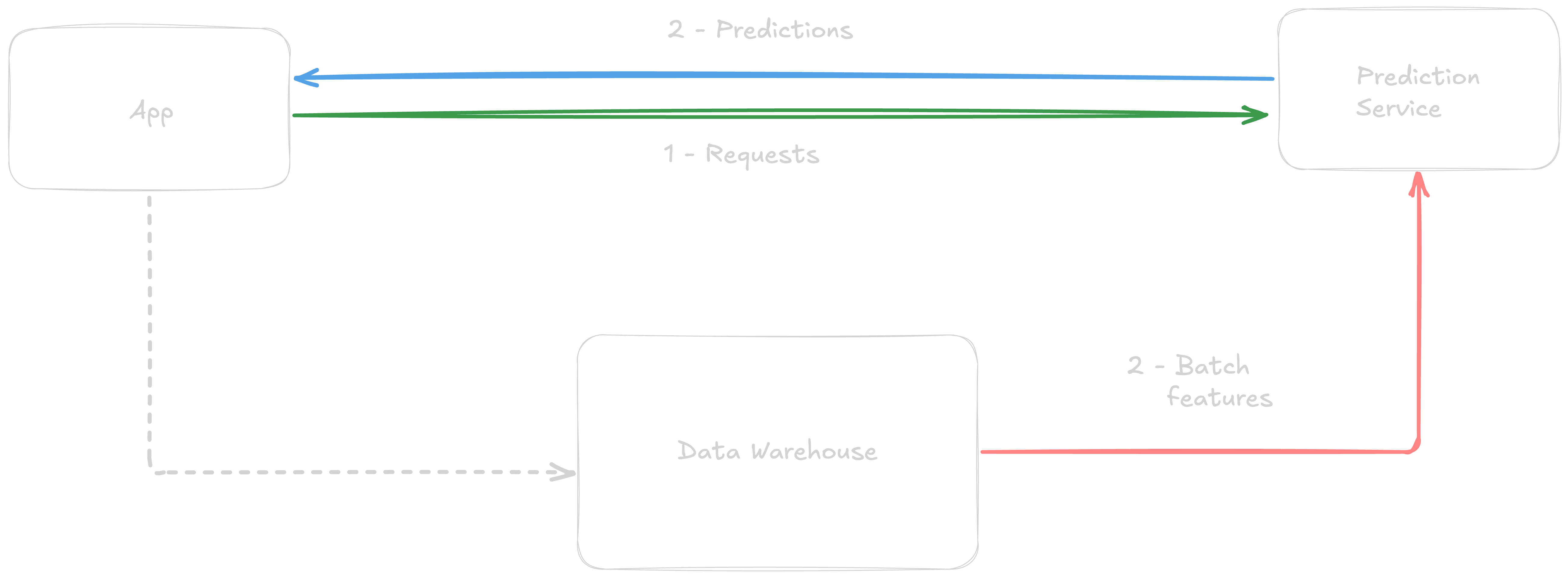
Online prediction using batch features
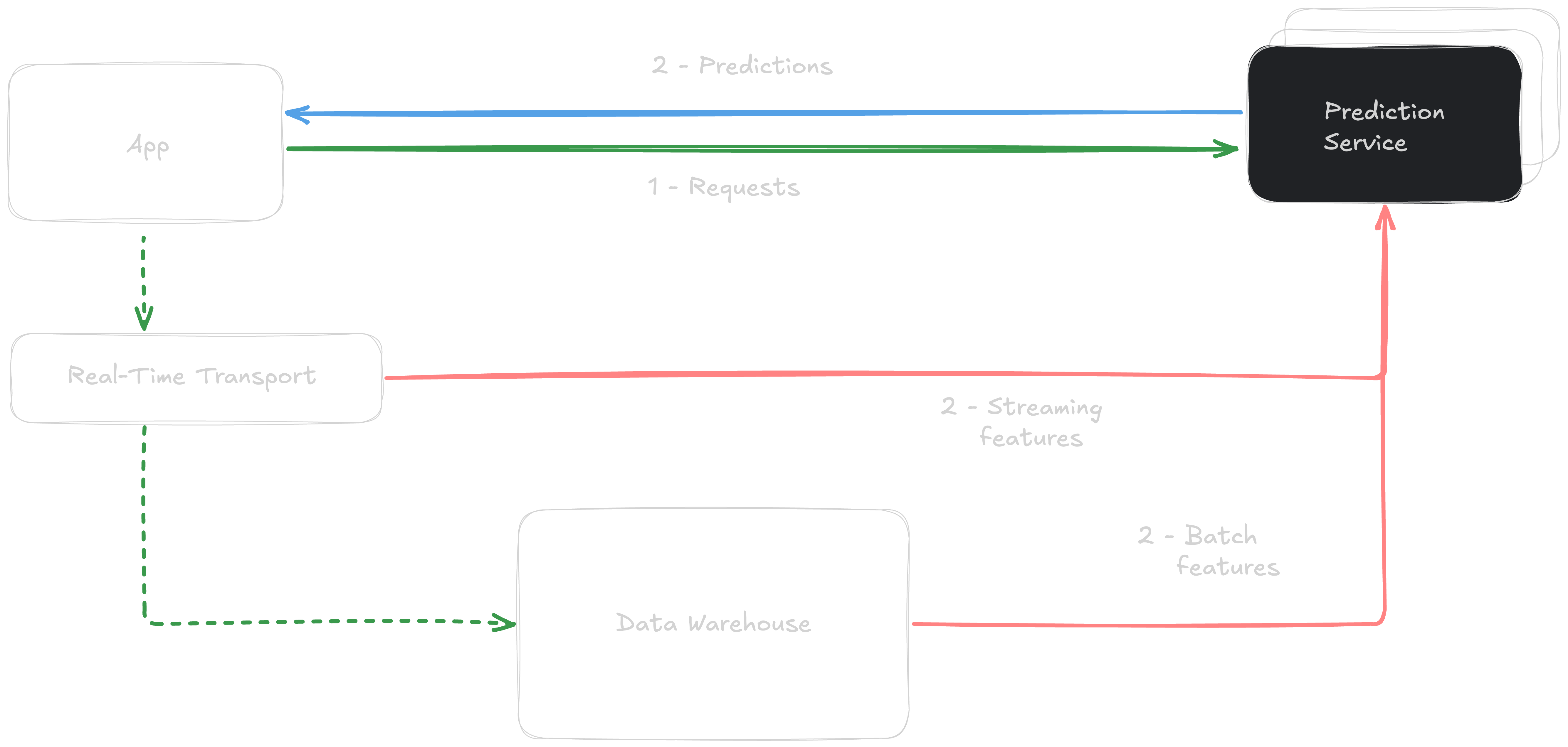
Online Prediction (Streaming)
Model Compression
- low rank factorization, e.g : compact conv filters
- knowledge distillation : student & teacher model
- pruning : by zeroing params, but can introduce biais
- quantization : using fewer bits to represent parameters
- Roblox Bert Case Study
ML on the Cloud VS On Device
ML Optimization on Edge
- vectorization
- parallelization
- loop tiling
- operator fusion
- graph optimization